Log Management: Graylog vs ELK

Whether you are a developer or a DevOps engineer, sooner or later you will need to check production logs which are usually scattered across different servers. What complicates the situation is that when data volume starts growing, management and maintenance of the environment can take a lot more time than you would want it to. Moreover, bigger data flows result in delayed insights on your project status. At this point, a question arises: what can I do to keep things in check?
The best way to avoid any mess without having to spend much time is to store server/application logs in one place. In this article, we’re going to make a comparison of two most popular open-source solutions that we use to simplify the logs management procedure: Graylog vs ELK (Elasticsearch+Logstash+Kibana).
But before we dive in, please check out our newly released landing page about our mobile app development expertise (we’ll really owe you for this one =)):
And now — let’s go!
Elasticsearch, Logstash, and Kibana

ELK is a combo of three separate services. All of them are open-source and developed by the same team.
- Elasticsearch is a very powerful and highly scalable search engine that can store large amounts of data and be used as a cluster.
- Logstash is a tool for fetching data from/to a specific location. Comes with a wide variety of plugins and a big user community.
- Kibana is a GUI that provides you the ability to search, analyze and visualize large amounts of complex data from the Elasticsearch database. The deployment process takes not more than 5 minutes.
Since we’re mainly interested in logs aggregation, we’ll probably skip the part about Elasticsearch. You can read about it in our previous blog posts here or here.
ELK in a nutshell
In most cases, the ELK stack uses Filebeat. The purpose of this tool is to deliver logs to a specific server. After they have been delivered with Filebeat and processed with Logstash, they are put into ElasticSearch cluster. From there, the logs are taken for visualization by Kibana. All the mentioned steps are described in the scheme below.

Logstash Pros
The reason why Logstash is so popular is because it can be easily integrated with other Elastic products. In addition, there is a whole bunch of plugins making this tool extremely flexible. It also comes with comprehensive documentation that has everything necessary for you configure and use Logstash in pretty much any case scenario. Finally, the installation procedure is very simple.
Logstash Cons
Logstash’s weak spot has always been performance and resource consumption. Though performance is now a lot better than a couple of years ago, it is still quite slow compared to other solutions. This can be an issue for high traffic deployments when Logstash servers would require to be comparable with the Elasticsearch ones. And the last but not least — Logstash has no GUI in the out-of-the-box version so you need to manually configure it by modifying the config files.
What about Kibana?
Since we used Kibana on one of our recent projects we decided why not include to include some screenshots on how to output and visualize data through this tool. And because the Internet is full of set-up tutorials like this one, we won’t dwell on this point and get straight to business.
The screen below is the place where you can choose the necessary visualization type.

After you’ve selected the type, you will be asked which index you want to get information from. The choice of index is based on what indexes are currently available in your ElasticSearch cluster.
On the screenshot below, you can see that you need to add the data or/and value fields depending on the kind of data there is. When it’s done, Kibana will output and visualize the statistics in the form of the chart selected.

In addition to storing data and visualizing it, we use Kibana to provide our clients with detailed information and statistics on how their applications work in a production environment.
Overall, ELK is a versatile combo. The stack can be used as a stand-alone application, or be integrated with existing applications to receive the most updated data.
Graylog

Graylog is a powerful tool for logs management that gives you lots of options on analyzing incoming logs from different servers. The way Graylog works is pretty much similar to ELK. In addition to the very Graylog server, which consists of the application and the web interface server, you will also need to have MongoDB and Elasticsearch in order to make the whole stack fully operable.
For production usage, we recommend installing all the components on different servers. This will improve stability and performance.
So, these are the ingredients you’ll need:
- Elasticsearch.
- MongoDB — a widely used database engine for storing configurations and metadata.
- Graylog main server — receives data from its clients installed on different servers.
- Graylog web interface — gives you access to the web interface that visualizes data and allows you to work with logs aggregated by the main server.
The configuration process consists of 2 steps:
- Creation of a tagged Graylog configuration to be used by the clients on the server side.
- Sending the configurations to the clients.
For instance, when you set up a client, you mark its configuration file with a “production” tag. After that, you create detailed configurations on the server for the clients with the “production” tag. Now all changes will be automatically picked up from the server as soon as you apply them, no other changes are required to be done on the client’s side.

As we said before, Graylog provides you with really good management options:
you can search for all the IP addresses blocked by a firewall for the past week, all the unsuccessful SSH logins. Further, you can create filters based on specified parameters. From our experience, this greatly simplifies the searching process in future.
Mind that creating a user is required to get into the web interface.
You need to configure “Inputs” from different servers which will send logs to your Graylog instance. These logs is where you will be extracting data from:

If you click “Show received messages” you will be taken directly to actual logs which were sent from the input source.
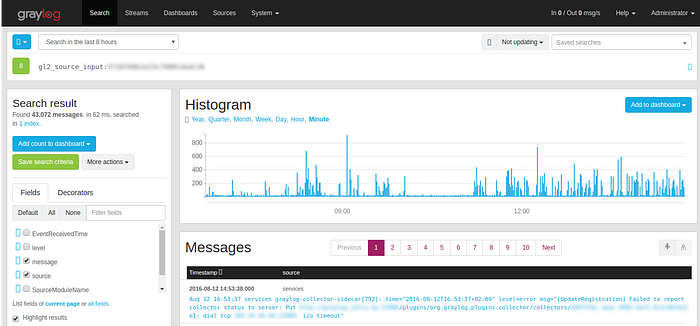
The search bar:

“gl2-source-input” specifies the exact source of your graylog client. You can type any query and it will filter logs in a way that only the necessary information will be shown. Also, there is a time filter. Say, you want to see if there was anything blocked from 12 am till 7 am on a particular server. That’s one of the reasons we’re using Graylog.
Graylog pros
It has a friendly GUI and supports a wide range of data formats. Provides you with good options to control authentication and user permissions. You can also configure it to receive alerts via emails. Finally, Graylog uses good-ol REST API.
Graylog cons
Graylog can’t read from syslog files, so you need to send your messages to Graylog directly. In terms of management, it’s not friendly enough on the dashboard front. Reporting functionality is quite poor.
Graylog vs ELK — which is better?
Both solutions are very similar in terms of a basic set of features. However, as Elasticsearch fans, we still prefer Graylog over ELK since it has a friendly GUI right out of the box and allows you to manage permissions. Also, Kibana has no feature to create users. However, we managed to solve this problem by setting up basic HTTP authentication in Nginx. It has a server running on a random port which forwards requests to your Kibana web interface.
